Loading... # 前言 代码见:https://github.com/4uiiurz1/pytorch-deform-conv-v2/blob/master/deform_conv_v2.py 论文:https://arxiv.org/abs/1703.06211 # 提出问题 为什么需要可变形卷积,他和普通卷积有什么差异,有什么优势? # 核心思想 原始图像通过卷积操作可以变成多通道的特征图,通过特征提取和分析可以完成不同的任务,传统卷积的基本流程如下图,卷积核在原特征图上遍历,加权平均后得到输出特征图相应位置的输出。如公式所示,如果是传统卷积,针对输出图的每个位置,原图上的采样位置是固定的,以3x3卷积核为例,相对采样位置就是公式中的R。 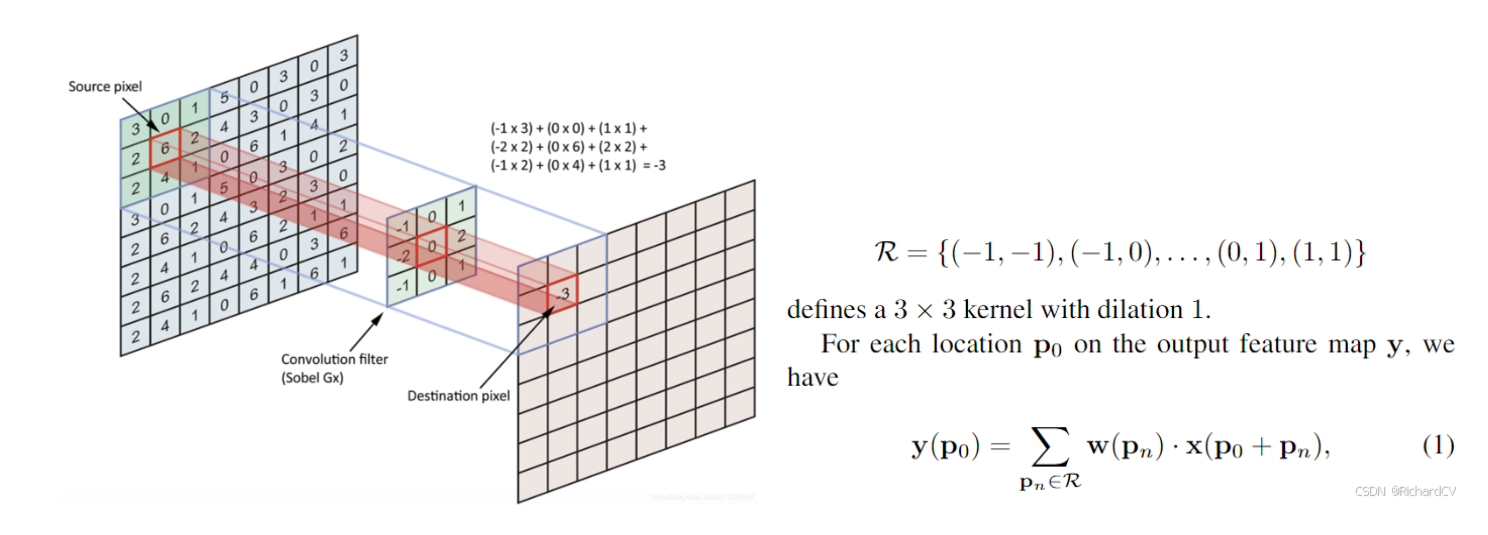 作者认为这种采样方式太规则了,不利于一些不规则特征的提取。例如下图所示,规则卷积vs 可变形卷积提取到的特征有较大区别。针对这个情况,作者提出可变形卷积,也就是说,采样的位置发生了一些变化,可以增加学习采样偏移量,如公式所示。xp代表着新的位置的值,通过bilinear插值得到。 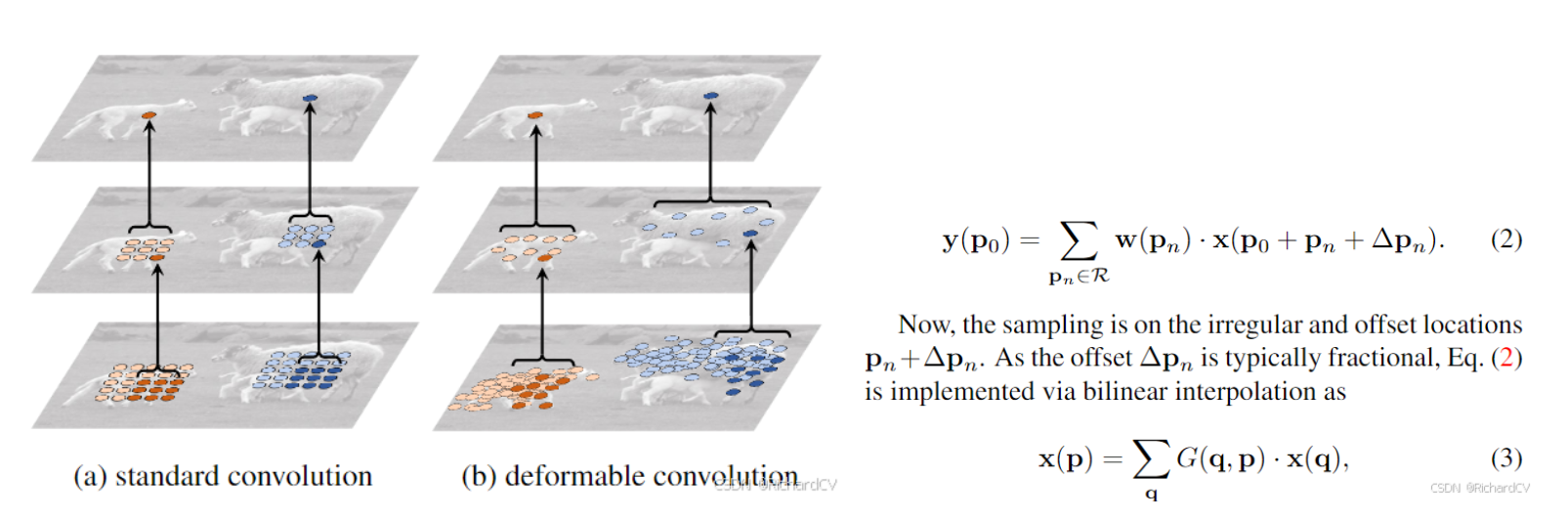 经过可变形卷积,整体的特征图尺寸不会发生变化,跟普通卷积一样,如下图所示。 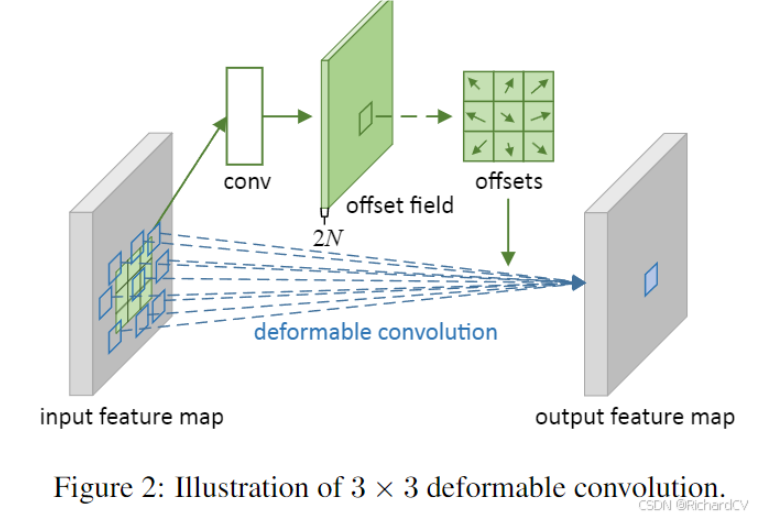 # 代码理解 整个原始代码难以理解的地方就是这个offset的计算,插值的计算,也就是最终用来卷积的这些数是怎么得到的。 ## 模块初始化 模块初始化设置三个卷积,`self.conv` 用来执行最后的卷积运算,`self.p_conv` 用来学习偏移量,`self.m_conv`用来给不同位置增加学习权重,代码及注意点和注释如下所示 ```python class DeformConv2d(nn.Module): def __init__(self, inc, outc, kernel_size=3, padding=1, stride=1, bias=None, modulation=False): """ Args: modulation (bool, optional): If True, Modulated Defomable Convolution (Deformable ConvNets v2). """ super(DeformConv2d, self).__init__() self.kernel_size = kernel_size self.padding = padding self.stride = stride self.zero_padding = nn.ZeroPad2d(padding) # 最终使用的卷积操作,注意stride=kernel, # 原因是最终采样点不是规则的点,需要结合通过偏移量取值,因此需要构建新的特征图 # 新的特征图的尺寸是原来特征图的hw 是原来hw x kernel_size 的大小 self.conv = nn.Conv2d(inc, outc, kernel_size=kernel_size, stride=kernel_size, bias=bias) # 用来学习偏移量的卷积,其中通道数为2xksxks ,如果k=3,也就是学习9个位置的2方向(x、y)偏移量 self.p_conv = nn.Conv2d(inc, 2*kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride) # 初始化偏移卷积为0 nn.init.constant_(self.p_conv.weight, 0) # 学习率设置为整个网络0.1倍,避免影响整体网络性能 self.p_conv.register_backward_hook(self._set_lr) # 为每个位置增加学习权重,初始化和偏移卷积一样 self.modulation = modulation if modulation: self.m_conv = nn.Conv2d(inc, kernel_size*kernel_size, kernel_size=3, padding=1, stride=stride) nn.init.constant_(self.m_conv.weight, 0) self.m_conv.register_backward_hook(self._set_lr) ``` ## forward过程 整体主要步骤如下 1、self.p_conv卷积计算offset ,# 维度 (b,2*ks*ks,h),w # 2xksxks 若k=3,也就是用来卷积的9的位置的x、y方向偏移 2、self._get_p 函数获取offset的位置 ( 绝对位置+相对位置)# 维度 (b, 2N, h, w) ,N=ksxks。 3、self._get_x_q 之前的函数用来计算双线性插值采样点,因为位置是浮点数,需要映射回具体坐标位置 # (b, c, h, w, N),不同的通道c其实对应相同的位置。# (b, c, h, w, N) 4、self._get_x_q 函数用来得到每个位置的插值权重 # (b, c, h, w, N) 5、self._reshape_x_offset 将b, c, h, w, N重新排布为b, c, hxks, wxks 用来进行最终的卷积 代码及解释如下。 ```python def forward(self, x): # b,c,h,w # 计算偏移量,维度 b,2*ks*ks,h,w # N=kxk offset = self.p_conv(x) if self.modulation: # 为偏移量增加权重 m = torch.sigmoid(self.m_conv(x)) dtype = offset.data.type() ks = self.kernel_size N = offset.size(1) // 2 # N=ks*ks # 填充:k=3的卷积,填充p=1,尺度才不会发生改变 if self.padding: x = self.zero_padding(x) # (b, 2N, h, w) ,得到p的位置 p = self._get_p(offset, dtype) # (b, h, w, 2N) ,位置放在最后一个维度,方便处理 p = p.contiguous().permute(0, 2, 3, 1) q_lt = p.detach().floor() #left top 左上角坐标,也就是最小值,如果是0-1之间就是0 q_rb = q_lt + 1 # right bottom右下角坐标,也就是最大值,如果是0-1之间就是1 # 确定四个角点坐标,设置在0 到 h-1 或 w-1 之间 q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2)-1), torch.clamp(q_lt[..., N:], 0, x.size(3)-1)], dim=-1).long() q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2)-1), torch.clamp(q_rb[..., N:], 0, x.size(3)-1)], dim=-1).long() q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1) q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1) # clip p ,采样点也需要clamp一下 p = torch.cat([torch.clamp(p[..., :N], 0, x.size(2)-1), torch.clamp(p[..., N:], 0, x.size(3)-1)], dim=-1) # bilinear kernel (b, h, w, N) g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:])) g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:])) g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:])) g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:])) # (b, c, h, w, N),计算四个领域的权重 x_q_lt = self._get_x_q(x, q_lt, N) x_q_rb = self._get_x_q(x, q_rb, N) x_q_lb = self._get_x_q(x, q_lb, N) x_q_rt = self._get_x_q(x, q_rt, N) # (b, c, h, w, N),计算插值结果 x_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \ g_rb.unsqueeze(dim=1) * x_q_rb + \ g_lb.unsqueeze(dim=1) * x_q_lb + \ g_rt.unsqueeze(dim=1) * x_q_rt # modulation,如果存在这个模块,就让偏移量*m if self.modulation: m = m.contiguous().permute(0, 2, 3, 1) m = m.unsqueeze(dim=1) m = torch.cat([m for _ in range(x_offset.size(1))], dim=1) x_offset *= m # 重新排列,变成 h,c,h*ks,w*ks 特征图,用来最后卷积 x_offset = self._reshape_x_offset(x_offset, ks) out = self.conv(x_offset) return out ``` ### self.p_conv 就是普通卷积操作,不进行解释 ### self._get_p 包括绝对位置和相对位置,绝对位置就是卷积中心在原图中的位置 0-(h-1) ,0-(w-1) ,相对位置就是0-(ks-1) ,卷积操作中每个点与中心位置的相对关系。 ```python def _get_p_n(self, N, dtype): # 相对位置 p_n_x, p_n_y = torch.meshgrid( torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1), torch.arange(-(self.kernel_size-1)//2, (self.kernel_size-1)//2+1)) # (2N, 1) p_n = torch.cat([torch.flatten(p_n_x), torch.flatten(p_n_y)], 0) p_n = p_n.view(1, 2*N, 1, 1).type(dtype) return p_n def _get_p_0(self, h, w, N, dtype): #绝对位置 p_0_x, p_0_y = torch.meshgrid( torch.arange(1, h*self.stride+1, self.stride), torch.arange(1, w*self.stride+1, self.stride)) p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1) p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1) p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype) return p_0 def _get_p(self, offset, dtype): N, h, w = offset.size(1)//2, offset.size(2), offset.size(3) # (1, 2N, 1, 1),相对位置只有2N个,因为就是卷积核大小 p_n = self._get_p_n(N, dtype) # (1, 2N, h, w),绝对位置有2NxHxW,因为每个位置都有偏移量 p_0 = self._get_p_0(h, w, N, dtype) p = p_0 + p_n + offset return p ``` ### self._get_x_q 将原始输入的hw变成一个维度的向量,相应的位置索引也需要变成一维,所以需要乘以w,然后最后在重新变成hxw格式 ```python def _get_x_q(self, x, q, N): b, h, w, _ = q.size() padded_w = x.size(3) c = x.size(1) # (b, c, h*w) x = x.contiguous().view(b, c, -1) # (b, h, w, N) index = q[..., :N]*padded_w + q[..., N:] # offset_x*w + offset_y # (b, c, h*w*N) index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1) x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N) return x_offset ``` ### self._reshape_x_offset 这个的理解可以根据这个博客@[链接](https://zhuanlan.zhihu.com/p/102707081)来,也就是将整体数据重新排布成卷积的类型 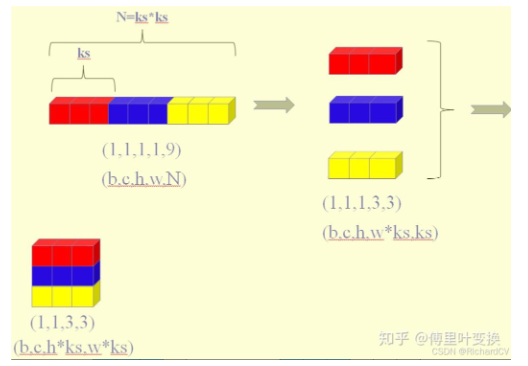 ```python @staticmethod def _reshape_x_offset(x_offset, ks): b, c, h, w, N = x_offset.size() x_offset = torch.cat([x_offset[..., s:s+ks].contiguous().view(b, c, h, w*ks) for s in range(0, N, ks)], dim=-1) x_offset = x_offset.contiguous().view(b, c, h*ks, w*ks) return x_offset ``` ## 参考文献 https://blog.csdn.net/panghuzhenbang/article/details/129816869 https://zhuanlan.zhihu.com/p/335147713 https://zhuanlan.zhihu.com/p/102707081 https://blog.csdn.net/panghuzhenbang/article/details/129816869 最后修改:2025 年 12 月 14 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
